FastCGI has many advantages, and it’s our preferred interface when it’s available for the required script language (such as PHP). However, we generally see environments where the php-fpm processes (for instance) are run on the same system as the web server, even though that’s not necessary. In FastCGI space, the web server (say nginx) passes a request through a socket or TCP/IP address:port, and the application delivers back an response (web page, web service JSON result, etc). Obviously sockets only work locally, but the port can be on another machine.
So the question is, how do you arrange your virtual server rack? While splitting things out like that tends to add a few ms of latency, the advantages tend to justify this approach:
Not running PHP on your web-server, and only having connectivity web-server -> application, is good for security:
should the web server get compromised, it can still only make application requests, not reconfigure the application server in any way;
should the application get compromised, it will not be able to gain control over the web-server as there is no connectivity path in that direction.
nginx is exceedingly good at “smart proxy”-style tasks, and that’s essentially already what it’s doing with FastCGI anyway;
you could have multiple application servers, rather than just one. Optionally scaled dynamically as traffic needs change;
this effectively turns nginx into a kind of load-balancer for the application server back-ends; the way you specify this is through
a single name that resolves to multiple address which are then used in a round-robin fashion (not necessarily optimal as some requests may take longer than others), or
a server group as provided by the ngx_http_upstream_module module.
nginx can detect when a back-end is unresponsive, and connect to an alternative;
thinking back to the fact that some requests take longer than others, that’s usually URL-specific. That is, it’s relevant for queries in certain areas (such as reporting, or drill-down type searches) of a web interface. Now, you can tell nginx to use a different FastCGI destination for those, and thus separate (insulate, really) the handling of that application traffic from the rest of the application.
This all fits very neatly with containers, should your infrastructure use those or if you’re considering moving towards containers and micro-services.
The possibilities are quite extensive, but naturally the details and available options will depend on your needs and what you already have in place. We regularly help our clients with such questions. Solutions Architecture, both for evolving existing environments as well as for greenfield projects.
I promised to do a pricing post on the Amazon RDS Aurora MySQL pricing, so here we go. All pricing is noted in USD (we’ll explain why)
We compared pricing of equivalent EC2+EBS server instances, and verified our calculation model with Amazon’s own calculator and examples. We use the pricing for Australia (Sydney data centre). Following are the relevant Amazon pricing pages from which we took the pricing numbers, formulae, and calculation examples:
“Volume storage for EBS Provisioned IOPS SSD (io1) volumes is charged by the amount you provision in GB per month until you release the storage. With Provisioned IOPS SSD (io1) volumes, you are also charged by the amount you provision in IOPS (input/output operations per second) per month. Provisioned storage and provisioned IOPS for io1 volumes will be billed in per-second increments, with a 60 second minimum.”
Storage Rate $0.138 /GB/month of provisioned storage “For example, let’s say that you provision a 2000 GB volume for 12 hours (43,200 seconds) in a 30 day month. In a region that charges $0.125 per GB-month, you would be charged $4.167 for the volume ($0.125 per GB-month * 2000 GB * 43,200 seconds / (86,400 seconds/day * 30 day-month)).”
I/O Rate $0.072 /provisioned IOPS-month “Additionally, you provision 1000 IOPS for your volume. In a region that charges $0.065 per provisioned IOPS-month, you would be charged $1.083 for the IOPS that you provisioned ($0.065 per provisioned IOPS-month * 1000 IOPS provisioned * 43,200 seconds /(86,400 seconds /day * 30 day-month)).”
Other Aurora pricing components
Storage Rate $0.110 /GB/month (No price calculation examples given for Aurora storage and I/O)
I/O Rate $0.220 /1 million requests (Presuming IOPS equivalence / Aurora ratio noted from arch talk)
So this provides us with a common base, instance types that are equivalent between Aurora and EC2. All other Aurora instances types are different, so it’s not possible to do a direct comparison in those cases. Presumably we can make the assumption that the pricing ratio will similar for equivalent specs.
On Demand vs Reserved Instances
We realise we’re calculating on the basis of On Demand pricing. But we’re comparing pricing within AWS space, so presumably the savings for Reserved Instances are in a similar ballpark.
Other factors
We have 720 hours in a 30 day month, which is 2592000 seconds.
70% read/write ratio – 70% reads (used to calculate the effective Aurora IOPS)
10% read cache miss -10% cache miss rate on reads
Aurora I/O ratio: 3 (Aurora requiring 2 IOPS for a commit vs 6 in MySQL – even though this is a pile of extreme hogwash in terms of that pessimistic MySQL baseline)
We also spotted this note regarding cross-AZ Aurora traffic:
“Amazon RDS DB Instances inside VPC: For data transferred between an Amazon EC2 instance and Amazon RDS DB Instance in different Availability Zones of the same Region, Amazon EC2 Regional Data Transfer charges apply on both sides of transfer.”
So this would apply to application DB queries issued across an AZ boundary, which would commonly happen during failover scenarios. In fact, we know that this happens during regular operations with some EC2 setups, because the loadbalancing already goes cross-AZ. So that costs extra also. Now you know! (note: we did not factor this in to our calculations.)
Calculation Divergence
Our model comes up with identical outcomes for the examples Amazon provided, however it comes up 10-15% lower than Amazon’s calculator for specific Aurora configurations. We presume that the difference may lie in the calculated Aurora I/O rate, as that’s the only real “unknown” in the model. Amazon’s calculator does not show what formulae it uses for the sub-components, nor sub-totals, and we didn’t bother to tweak until we got at the same result.
It’s curious though, as the the architecture talk makes specific claims about Aurora’s I/O efficiency (which presume optimal Aurora situation and a dismal MySQL reference setup, something which I already raised in our initial Aurora post). So apparently the Amazon calculator assumes worse I/O performance than the technical architecture talk!
Anyhow, let’s just say our costing is conservative, as the actual cost is higher on the Aurora end.
Scenarios
Here we compare with say a MySQL/MariaDB Galera setup across 3 AZs running on EC2+EBS. While this should be similar in overall availability and read-capacity, note that
you can write to all nodes in a Galera cluster, whereas Aurora currently has a single writer/master;
When using the Amazon calculator, Aurora comes out at about double the EC2. But don’t take our word for it, do try this for yourself.
Currency Consequences
While pricing figures are distinct per country that Amazon operates in, the charges are always in USD. So this means that the indicated pricing is, in the end, in USD, and thus subject to currency fluctuations (if your default currency is not USD). What does this mean?
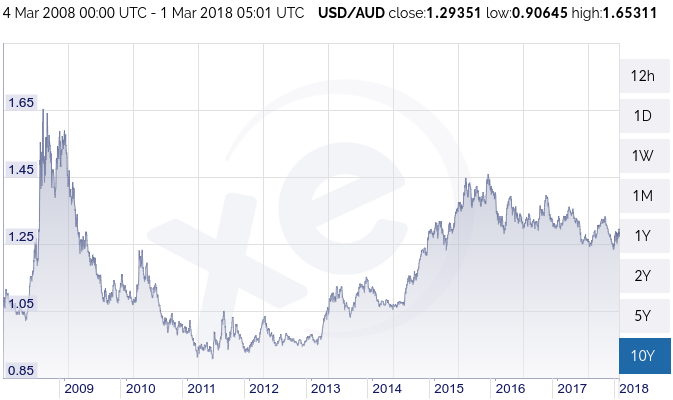
USD-AUD rate chart 2008-2018, from xe.com
So USD 1,000 can cost as little as AUD 906 or as much as AUD 1,653, at different times over the last 10 years. That’s quite a range!
Conclusion
As shown above, our calculation with Aurora MySQL shows it costing about twice as much. This is based on a reference MySQL/MariaDB+Galera with roughly the same scaling and resilience profile (e.g. the ability to survive DC outages). In functional terms, particularly with Aurora’s 30+second outage profile during failover, Galera comes out on top at half the cost.
So when is Aurora cheaper, as claimed by Amazon?
Amazon makes claims in the realm of “1/10th the cost”. Well, that may well be the case when comparing with the TCO of Oracle or MS SQL Server, and it’s fairly typical when comparing a proprietary system with an Open Source based one (mind again that Aurora is not actually Open Source as Amazon does not make their source code available, but it’s based on MySQL).
The only other way we see is to seriously compromise on the availability (resilience). In our second sample calculation, we use 2 instances per AZ. This is not primarily for performance, but so that application servers in an AZ don’t have to do cross-DC queries when one instance fails. In the case of Aurora, spinning up a new instance on the same dataset requires 15 minutes. So, do you want to take that hit? If so, you can save money there. If not, it’s still costly.
But hang on, if you’re willing to make the compromise on availability, you could reduce the Galera setup also, to only one instance per AZ. Yep!
So, no matter how you tweak it, Aurora is about twice the cost, with (in our opinion) a less interesting failover profile.
The Price of RDS Convenience
What you get with RDS/Aurora is the promise of convenience, and that’s what you pay for. But, mind that our comparison worked all within AWS space anyway, the EC2 instances we used for MySQL/MariaDB+Galera already use the same basic infrastructure, dashboard and management API as well. So you pay double just to go to RDS/Aurora, relative to building on EC2.
To us, that cost seems high. If you spend some, or even all that money on engineering that convenience around your particular setup, and even outsource that task and its maintenance, you get a nicer setup at the same or a lower cost. And last but not least, that cost will be more predictable – most likely the extra work will be charged in your own currency, too.
Cost Predictability and Budget
You can do a reasonable ball-park calculation of AWS EC2 instances that are always active, but EBS already has some I/O charges which make the actual cost rather more variable, and Aurora adds a few more variables on top of that. I’m still amazed that companies go for this, even though they traditionally prefer a known fixed cost (even if higher) over a variable cost. Choosing the variable cost breaks with some fundamental business rules, for the sake of some convenience.
The advantage of known fixed costs is that you can budget properly, as well as project future costs based on growth and other business factors. Purposefully ditching that realm, while exposing yourself to currency fluctuations at the same time, seems most curious. How do companies work this into their budgets? Because others do so? Well, following the neighbours is not always a good idea. In this case, it might be costly as well as financially risky.
Right now we’re volunteering some engineering time to assisting the WordPress and WooCommerce people with scalability issues. In the past we’ve put similar efforts into Drupal.
There are many opinions on these systems out there, most of them sadly negative. We take a different view. Each of these frameworks obviously has their advantages and disadvantages, but the key question is why people use them. When we understand that, we can assess that reasoning, and assist further.
Obviously writing your own code all the way is going to potentially create the most optimal result for your site. A custom tool is going to be less code and more optimal for your situation. However, it also requires you to put in quite a bit of development effort both to create and to maintain that system, including security issues. When you’re big enough (as a site/company) this can be worthwhile, but more and more organisations actually appear to be moving towards utilising a CMS and then extending that to their needs using the usual module/plugin/extension model.
This also means that bigger and bigger sites use these systems, and thus we need to look at the scalability. CMS frameworks tend to be “db heavy”, caused by being highly configurable combined with a modular/abstraction architecture that sometimes goes for “code architectural correctness” without taking scaling into account. Naturally most such code works fine on a dev box and even on a modest live server. But add sufficient content, and things rapidly go downhill. Just like with other database related tuning issues, there is no gradual degradation in performance – when certain boundaries are reached, performance plummets to cause nasty page load times or even complete page load failures.
Are these systems inherently dreadful? Actually, no. They do a darn good job and even in security terms they’re not bad at all. Naturally one always has to be careful with modules/plugins and whether they are (still) maintained.
So, with that assessment out of the way – we can look at the actual issues. It makes sense for us to contribute to these systems as it directly benefits our clients, ourselves, and many many others.
Just no the option structure in WordPress has drawn our interest. It’s abstracted, and so a plugin will request the value of an individual option item (by name). Typically it causes a db query. WordPress has an ‘autoload’ mechanism particularly for its core settings, which it loads in one bigger query and caches – that makes sense.
We’ve just commented on an existing issue regarding the indexing of the autoload column, with people arguing that indexing a boolean field is not beneficial (not necessarily true and easily tested for a specific case – the outcomes is that in this case an index IS beneficial) and that having more indexes slows down writes (true of course, but that’s never an argument against proper indexing – also this is mostly a read table, so a bit of overhead on writes is fairly immaterial). Lastly there were comments re MyISAM which has a slightly different performance profile to InnoDB when testing this. But InnoDB has been the default engine for quite a few years now – any installation in recent years, and any installation where the owner needs to care for more performance and other factors, will already be using InnoDB. Taking MyISAM into account is not beneficial. We hope the index will shortly be added. In the mean time you can add it yourself:
ALTER TABLE wp_options ADD INDEX (autoload)
Using autoload for everything would not be efficient, there can be tens of thousands of options in a decently sized site. So we see plugins retrieve half a dozen options, one by one using the appropriate framework function, and each triggers a database query. Again we have to appreciate why this architecture is the way it is, and not waste time on arguing with that. There are sensible reasons for having such an option architecture. What we need to address is the inefficiency of triggering many queries.
Our proposal is to extend the get_option() function with an extra parameter for a plugin name (call it a domain), then the function can issue a single db query to retrieve all the options for that plugin and cache it in a single object. When another option is requested it can be retrieved from there rather than triggering another query. This reduces the number of db queries from N per plugin to 1, which is significant. Mind you, each of these queries is tiny and doesn’t require much lookup time. But running any query has intrinsic overhead so we want to reduce the number of queries whenever possible – not running superfluous queries, combining queries, and so on.
There are variations on the proposal as there are many aspects to consider, but it’s important to not leave it “as is” as currently it affects performance and scalability.
So how do we catch potential items of interest? On the database end, the slow query log is still very useful with the proper settings. log_queries_not_using indexes, min_examined_row_limit=1000 (tune appropriate for the environment), log_slow_filter and log_slow_verbosity to give as much info as possible, and long_query_time to something sub-second. Naturally, this presumes you’ve already taken care of real nasties otherwise you’ll get very big slow log files very quickly. You can analyse the slow query log using Percona Tools, but the ‘mysqldumpslow’ tool which is part of the server package is pretty useful also. You’re looking for queries that either take a long time, or that happen often, or just look odd/inefficient/unnecessary. Then hunt where they come from in the code, and figure out the why. Often reasons aren’t necessarily good or current (historical scenarios linger), but there will be reasons and understanding them will help you talk with developers more effectively – seeing where they come from.
WordPress has a nice plugin called Query Monitor. As admin you get details from a page load in your top admin bar, and you can delve into specific aspects. Things to look out for are an excessive number of queries for a page (a hundred is sadly common, but when you see into the thousands it’s worthwhile investigating – of course, start with the biggest problems first and work your way down), duplicated queries (indicating framework inefficiencies) and things like that. Have a good browse around, there’s much there that’s useful.
If you want, feel free to bring suspected issues to our attention. We’ll look at them, perhaps write about them here, and in any case follow up with the developers in their bug tracking system. It’s worthwhile.
Open Source is a whole-of-process approach to development that can produce high-quality products better tailored to users’ real world needs. A key reason for this is the early feedback cycle built into that complete process.
Simply publishing something under an Open Source license (while not applying Open Source development processes) does not yield the same quality and other benefits. So, not all Open Source is the same.
Publishing source of a product “later” (for instance when the monetary benefit has diminished for the company) is meaningless. In this scenario, there is no “Open Source benefit” to users whatsoever, it’s simply a proprietary product. There is no opportunity for the client to make custom modifications or improvements, or ask a third party to work on such matters – neither is there any third party opportunity to verify and validate either code quality or security.
Open Source is not a marketing gimmick. Labels such as “Open Source”, or “Enterprise”, on their own, do not have any more positive outcome than a greasy hamburger labeled with “healthy”. If a company “believes” in Open Source software, they’ll use the open source development model for their software development.
So what does it mean when a company publishes some of their software under an open source license, and does some related products under a proprietary license? To me, it’s generally a strong indication that the company either doesn’t believe in that model, or doesn’t understand it. And we’ve seen it before.
It also reminds me of an interaction I had many years ago. A Marketing VP asked me “How can we leverage our [Open Source] community?” I answered the only possible way: “One does not ‘leverage’ the community, that’s not how it works.” Of course that wasn’t the answer the VP wanted to hear, but that doesn’t make it less true. They saw the community as an asset to use, rather than work with. People don’t like getting used, and in the Open Source space that’s even more true.
Companies that have turned their back on their earlier Open Source work and who have devised some other model to (arguably) make more money, have all discovered that this fundamentally changes their market. They’ll lose some of their users, customers and supporters, and gain some new different clients. It’s a different market. Whether and how that pans out in terms of commercial success is never certain. Given that we know that the Open Source development process yields benefits in terms of quality and features users want, we can say that non-OSS products lack (some of) those benefits, so to put it bluntly, it’ll be a different product of possibly less quality and the feature set is likely to differ as well.
Naturally we cannot ascertain code quality directly as we can’t review closed code directly, bug systems of proprietary software tends to be closed, changelogs are condensed for marketing purposes, but as far back as a decade and a half there have been independent studies that worked out “lines of code per software flaw” and it came out significantly in favour of Open Source software, having proportionally much fewer bugs. Bugs also tend to get fixed quicker in Open Source software. None of this is new(s). see for instance Open-source vs. proprietary software bugs: Which get squashed fastest? (CNET, 2007)
For complete products (libraries are a slightly different beast) with a relatively large market scope, source code being available does not in any way diminish a company’s ability to make money. Having the core developers, tech writers and support people gives them a significant edge in the open market, and that’s a business asset you can leverage. You do that by focusing on those aspects in your communications – that’s basic marketing, you draw attention to the positive aspects that make your company/product stand out from the rest. Clearly, this objective cannot not achieved by force, as you don’t make a (potential) client like or trust you by denying them choice or transparency.
There is one other known option aside from not believing or not understanding, and that’s fear. But fear is an awkward business driver, it makes for very bad decisions.
MariaDB Corp in part uses the Open Source development model, in part they’re an Open Source publisher (in-house work that’s only made available at a later stage in the development process), and now some proprietary product has been added to the mix (actually new versions of an existing product). Looking at this I am rather unclear about what they believe in. Of course companies can make business choices as they see fit – but they never operate in a vacuum. In the end it doesn’t matter much what I believe personally, the market will do what it will – historically, it responds in the various ways as described above. We’ll see how it pans out.
Open Query does not recommend (or re-sell at all) proprietary tools, as it just doesn’t make sense for us or our clients. We often do bugfixes and improvements which we contribute upstream – for proprietary tools we can’t do that and thus it becomes a hindrance for us and our clients. On the specific practical level, we’ve actually never used MaxScale (the product that MariaDB Corp will now sell under different conditions for future versions), and this stems from our experience with its effective predecessor MySQL Proxy. Having a complex set of scripted logic in a proxy slows down applications and introduces a rather large extra (single) point of potential failure in to infrastructure. So, while Simon refers to MaxScale as an essential tool for scale-able environments, we know from experience that there are other ways of achieving that desired objective, and without the downsides.
Rather than promoting a single tool for many wildly different jobs, we utilise a few different tools depending on the needs of particular client infrastructure. We still have a couple of (now legacy) MySQL-MMM deployments, but also quite a few Galera clusters, and other setups as suit our clients’ needs. Key is to not only make the infrastructure convenient to use for applications, but also to not introduce any more single points of failure. We build resilience into the client’s server infrastructure, without adding significant overhead in either performance or maintenance requirements.
We believe that that’s what clients want, and since potential clients come to us asking exactly for that (and note our approach with relief) we think that we’re doing the right thing by our clients. We’ve used this approach for over 9 years, and we’ll just keep on doing that – our basic approach doesn’t change even when our tools do. If you’d like to talk with us about helping you with your infra, using our approach and way of working, contact us today!
Colourful language aside, I believe he rightfully points out the failings of the organising company and the big Australian retailers. From the Open Query perspective we can just review the situation where sites fall over under load. Contrary to what they say, that’s not a cool indication of popularity. Let’s compare with the real world:
Brick & Mortar store does something that turns out popular and we see a huge queue outside, people need to wait for hours. The people in the queue can chat, and overall the situation can be regarded as positive: it shows passers-by that there’s something special going on, and that’s cool. If you don’t want to be in the crowd, you’ll come back later.
Website is unresponsive/inaccessible. There’s nothing cool or positive about this, as the cause is not only unknown, but in fact irrelevant in the context. Each potential client is on their own. Things fail, so they go elsewhere (if there are substitutes) or potentially away completely (concert, it’ll sell out). The bad taste sticks, so if there are alternatives they will not only move there, but be quite vocal about it so others move also.
So you see, you really don’t want your site to go down because of popularity, or for any other reason. Slashdot years ago created a “degrade gracefully” mechanism, where parts of the site would go static. So where normally users would be able to comment and rate posts, they’d just be able to read. In the worst case, only the front page would remain active. On Sept 11 2001, Slashdot was one of the few big sites that actually remained accessible and provided regular news that people could then read even though the topic was not really in its normal scope. The point is, they proved the approach multiple times.
Contrarily, companies like Ticketek have surely got Enterprise Design architecture, however their site has been seen to fall over with events such as The Wiggles. They might be able to get away with this since they’re essentially a monopoly provider: if you want a ticket for this particular event, you need to go to them. But it’s not good. Generally they acted surprised, even though the huge load was entirely predictable. Is that just naive, or a hope to mislead the public, or negligent? You decide.
It’s really a failure in design of sorts. As to where exactly, only an architectural review would show, and it’ll be different for different sites. However, the real lesson is that it’s not about “Enterprise Design” at all, nor about using any particular high-profile hosting provider or involvement of other buzzwords. It’s about proper architecture and deployment and the database is only one aspects of this. It doesn’t have to end up particularly expensive either, it just has to be done right and there’s no single magical approach – each case is unique. Looking at this is best done early on (it tends to also work our better and cheaper), but we’ve helped clients out at much later stages also. Ideally, we do like to help before there’s a raging fire.
Tumblr is one of the largest users of MySQL on the web. At present, our data set consists of over 60 billion relational rows, adding up to 21 terabytes of unique relational data. Managing over 200 dedicated database servers can be a bit of a handful, so naturally we engineered some creative solutions to help automate our common processes.
Today, we’re happy to announce the open source release of Jetpants, Tumblr’s in-house toolchain for managing huge MySQL database topologies. Jetpants offers a command suite for easily cloning replicas, rebalancing shards, and performing master promotions. It’s also a full Ruby library for use in developing custom billion-row migration scripts, automating database manipulations, and copying huge files quickly to multiple remote destinations.
Dynamically resizable range-based sharding allows you to scale MySQL horizontally in a robust manner, without any need for a central lookup service or massive pre-allocation of tiny shards. Jetpants supports this range-based model by providing a fast way to split shards that are approaching capacity or I/O limitations. On our hardware, we can split a 750GB, billion-row pool in half in under six hours.
Good work Tumblr, excellent move to open up your tools: you’re bound to get good feedback and bug catches/fixes from users in other environments now, making your toolset even better!
Earlier this week, Andrew Morgan wrote a piece on running MySQL Cluster on Raspberry Pi. Since the term “Cluster” is hideously overloaded, I’ll note that we’re talking about the NDB cluster storage engine here, a very specific architecture originally acquired by MySQL AB from Ericsson (telco).
Raspberry Pi is a new single-board computer based on the ARM processor series (same stuff that powers most mobile phones these days), and it can run Linux without any fuss. Interfaces include Ethernet, USB, and HDMI video, and the cost is $25-50. I’m looking to use one for the front-end of a MythTV setup (digital video recorder and TV system), I can just strap the Raspberry Pi to the back of a TV or monitor to do its job.
As Andrew already notes, in practical terms you’re not likely to use Raspberry Pi for a cluster – perhaps for development and certain testing, and it’d be a neat solid state management server. Primarily, it’s “techie cool”.
Knowing the NDB architecture, one of the key issues is that all nodes need to communicate with each other (NxN) so the system is very network intensive, and network latency significantly affects performance. So commonly, a cluster would have at least separate interfaces for direct connections to its siblings (no switch), and possibly Dolphin Interconnect cards to provide a link with much less latency than regular Ethernet offers. And you can’t do either with Raspberry Pi.
However, there are important positive lessons in this setup:
Using the open source nature of the software it can be utilised in a new environment with only minimal tweaks. Not everybody needs to or wants to tweak, but the ability to do so is critical to innovation.
Overall, scaling out rather than up makes sense. There are cost, power-efficiency and other factors involved. More, cheap, relatively low-powered, systems can deliver a system architecture that would otherwise be unaffordable (and the expensive construct might not scale anyway).
Affordable resilience (redundancy).
What if you needed lots of MySQL slaves with a fairly small dataset? Raspberry Pi could well be the solution. Not everybody is “big” or “high performance” in the same way.
In 2007, Etsy made a big bet on homegrown middleware to help with the site’s scalability. A half-year after it was taken live, the company decided to abandon it. As a senior software engineer at Etsy put it, “if you’re doing something ‘clever,” you’re probably doing it wrong.”
I want to focus on the important lessons from this article, about middleware and using stored procedures in this fashion for a public web application, creating unscalable design complexity (smart and “proper” according to the old enterprise design teachings…) – causing infrastructure, development and maintenance hassles.
In the process they did replace PostgreSQL with MySQL but that’s not the critical change that made all the difference. PostgreSQL is a fine database system also.
I spent some time earlier this week trying to debug a permissions problem in Drupal.
After a lot of head-scratching, it turned out that Drupal assumes that when you run INSERT queries sequentially on a table with an auto_increment integer column, the values that are assigned to this column will also be sequential, ie: 1, 2, 3, …
This might be a valid assumption when you are the only user doing inserts on a single MySQL server, but unfortunately that is not always the situation in which an application runs.
I run MySQL in a dual-master setup, which means that two sequential INSERT statements will never return sequential integers. The value will always be determined by the auto_increment_increment and auto_increment_offset settings in the configuration file.
In my case, one master will only assign even numbers, the other only uneven ones.
My patch was accepted, so this problem is now fixed in the Drupal 7 (and hopefully soon in 6 as well) codebase.
The moral of the story is that your application should never make such assumptions about auto_increment columns. A user may run the application on a completely different architecture, and it may break in interesting and subtle ways.
If you want to use defined integers like Drupal does, make sure you explicitly insert them. Otherwise, you can retrieve the assigned number via the mysql_insert_id() function in PHP or via SELECT LAST_INSERT_ID() in MySQL itself.
Ronald Bradford last week posted about memcached not being multi-threaded on Ubuntu, something he discovered via some small utilities that are bundled with libmemcached, written by Brian Aker.
When I noticed there were no Ubuntu packages for libmemcached (or the CLI tools) I decided to create some.

 FastCGI has many advantages, and it’s our preferred interface when it’s available for the required script language (such as PHP). However, we generally see environments where the php-fpm processes (for instance) are run on the same system as the web server, even though that’s not necessary. In FastCGI space, the web server (say nginx) passes a request through a socket or TCP/IP address:port, and the application delivers back an response (web page, web service JSON result, etc). Obviously sockets only work locally, but the port can be on another machine.
FastCGI has many advantages, and it’s our preferred interface when it’s available for the required script language (such as PHP). However, we generally see environments where the php-fpm processes (for instance) are run on the same system as the web server, even though that’s not necessary. In FastCGI space, the web server (say nginx) passes a request through a socket or TCP/IP address:port, and the application delivers back an response (web page, web service JSON result, etc). Obviously sockets only work locally, but the port can be on another machine. I promised to do a pricing post on the Amazon RDS Aurora MySQL pricing, so here we go. All pricing is noted in USD (we’ll explain why)
I promised to do a pricing post on the Amazon RDS Aurora MySQL pricing, so here we go. All pricing is noted in USD (we’ll explain why)