This blag was originally posted at http://cafuego.net/2010/05/26/fast-paging-real-world
Some time ago I attended the “Optimisation by Design” course from Open Query¹. In it, Arjen teaches how writing better queries and schemas can make your database access much faster (and more reliable). One such way of optimising things is by adding appropriate query hints or flags. These hints are magic strings that control how a server executes a query or how it returns results.
An example of such a hint is SQL_CALC_FOUND_ROWS. You use it in a select query with a LIMIT clause. It instructs the server to select a limited numbers of rows, but also to calculate the total number of rows that would have been returned without the limit clause in place. That total number of rows is stored in a session variable, which can be retrieved via SELECT FOUND_ROWS(); That simply reads the variable and clears it on the server, it doesn’t actually have to look at any table or index data, so it’s very fast.
This is useful when queries are used to generate pages of data where a user can click a specific page number or click previous/next page. In this case you need the total number of rows to determine how many pages you need to generate links for.
The traditional way is to first run a SELECT COUNT(*) query and then select the rows you want, with LIMIT. If you don’t use a WHERE clause in your query, this can be pretty fast on MyISAM, as it has a magic variable that contains the number of rows in a table. On InnoDB however, which is my storage engine of choice, there is no such variable and consequently it’s not pretty fast.
Paging Drupal
At DrupalConSF earlier this year I’d floated the idea of making Drupal 7 use SQL_CALC_FOUND_ROWS in its pager queries. These are queries generated specifically to display paginated lists of content and the API to do this is pretty straightforward. To do it I needed to add query hint support to the MySQL driver. When it turned out that PostgreSQL and Oracle also support query hints though, the aim became adding hint support for all database drivers.
That’s now done, though only the patch only implements hints on the pager under MySQL at the moment.
One issue keeps cropping up though, a blog by Alexey Kovyrin in 2007 that states SELECT COUNT(*) is faster than using SQL_CALC_FOUND_ROWS. It’s all very well to not have a patch accepted if that statement is correct, but in my experience that is in fact not the case. In my experience the stats are in fact the other way around, SQL_CALC_FOUND_ROWS is nearly always faster than SELECT COUNT(*).
To back up my claims I thought I should run some benchmarks.
I picked the Drupal pager query that lists content (nodes) on the content administration page. It selects node IDs from the node table with a WHERE clause which filters by the content language. Or, in plain SQL, what currently happens is:
SELECT COUNT(*) FROM node WHERE language = 'und';
SELECT nid FROM node WHERE language = 'und' LIMIT 0,50;
and what I’d like to happen is:
SELECT SQL_CALC_FOUND_ROWS nid FROM node WHERE language = 'und' LIMIT 0,50;
SELECT FOUND_ROWS();
Methodology
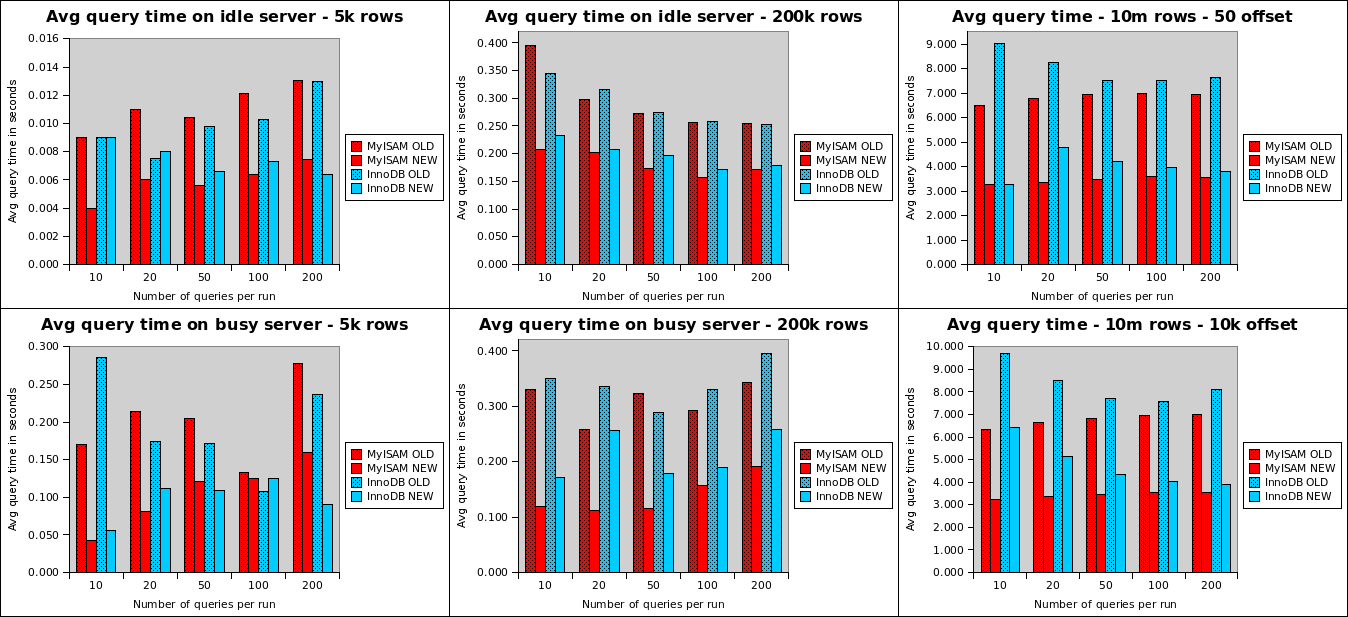
I ran two sets of tests. One on a node table with 5,000 rows and one with 200,000 rows. For each of these table sizes I ran a pager with 10, 20, 50, 100 and 200 loops, each time increasing the offset by 50; effectively paging through the table. I ran all these using both MyISAM and InnoDB as the storage engine for the node table and I ran them on two machines. One was my desktop, a dual core Athlon X2 5600 with 4Gb of RAM and the other is a single core Xen virtual machine with 512Mb of RAM.
I was hoping to also run tests with 10,000,000 rows, but the virtual machine did not complete any of the queries. So I ran these on my desktop machine only. Again for 10, 20, 50, 100 and 200 queries per run. First with an offset of 50, then with an offset of 10,000. I restarted the MySQL server between each run. To discount query cache advantages, I ran all tests with the query cache disabled. The script I used is attached at the bottom of this post. The calculated times do include the latency of client/server communication, though all tests ran via the local socket connection.
My desktop runs an OurDelta mysql .5.0.87 (the -d10-ourdelta-sail66) to be exact. The virtual machine runs 5.0.87 (-d10-ourdelta65). Before you complain that not running a vanilla MySQL invalidates the results, I run these because I am able to tweak InnoDB a bit more, so the I/O write load on the virtual machine is somewhat reduced compared to the vanilla MySQL.
Results
The graphs show that using SQL_CALC_FOUND_ROWS is virtually always faster than running two queries that each need to look at actual data. Even when using MyISAM. As the database gets bigger, the speed advantage of SQL_CALC_FOUND_ROWS increases. At the 10,000,000 row mark, it’s consistently about twice as fast.
Also interesting is that InnoDB seems significantly slower than MyISAM on the shorter runs. I say seems, because (especially with the 10,000,000 row table) the delay is caused by InnoDB first loading the table from disk into its buffer pool. In the spreadsheet you can see the first query takes up to 40 seconds, whilst subsequent ones are much faster. The MyISAM data is still in the OS file cache, so it doesn’t have that delay on the first query. Because I use innodb_flush_method=O_DIRECT, the InnoDB data is not kept in the OS file cache.
Conclusion
So, it’s official. COUNT(*) is dead, long live SQL_CALC_FOUND_ROWS! 🙂
I’ve attached my raw results as a Gnumeric document, so feel free to peruse them. The test script I’ve used is also attached, so you can re-run the benchmark on your own systems if you wish.
Conclusion Addendum
As pointed out in the Drupal pager issue that caused me to run these tests, the query I’m benchmarking uses the language column, which is not indexed and the test also doesn’t allow the server to cache the COUNT(*) query. I’ve rerun the tests with 10 million rows after adding an index and I no longer get a signification speed difference between the two ways of getting the total number of rows.
So I suppose that at least SQL_CALC_FOUND_ROWS will cause your non-indexed pager queries to suck a lot less than they might otherwise and it won’t hurt if they are properly indexed 🙂
¹ I now work for Open Query as a consultant.