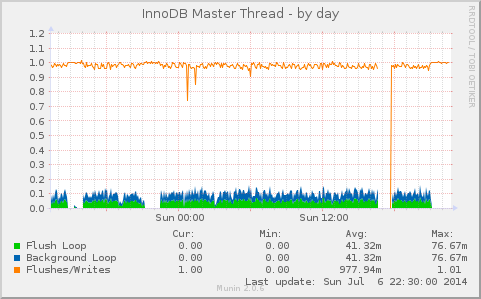
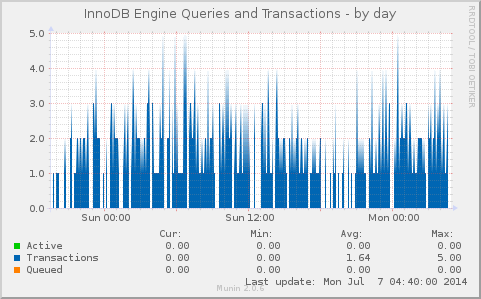
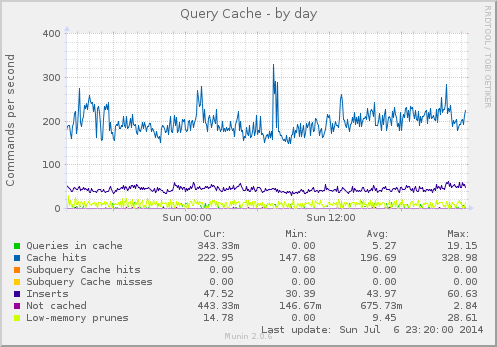
We deploy Galera Cluster (in MariaDB) for some clients, and innodb_flush_logs_on_trx_commit is one of the settings we’ve been playing with. The options according to the manual:
- =0 don’t write or flush at commit, write and flush once per second
- =1 write and flush at trx commit
- =2 write log, but only flush once per second
The flush (fsync) refers to the mechanism the filesystem uses to try and guarantee that written data is actually on the physical medium/device and not just in a buffer (of course cached RAID controllers, SANs and other devices use some different logic there, but it’s definitely written beyond the OS space).
In a non-cluster setup, you’d always want it to be =1 in order to be ACID compliant and that’s also InnoDB’s default. So far so good. For cluster setups, you could be more lenient with this as you require ACID on the cluster as a whole, not each individual machine – after all, if one machine drops out at any point, you don’t lose any data.
Codership docu recommended =2, so that’s what Open Query engineer Peter Lock initially used for some tests that he was conducting. However, performance wasn’t particularly shiny – actually not much higher than =1. That in itself is interesting, because typically we regard the # of fsyncs/second a storage system can deal with as a key indicator of performance capacity. That is, as our HD Latency tool shows when you run it on a storage device (even your local laptop harddisk), the most prominent aspect of what limits the # of writes you can do per second appears to be the fsyncs.
I then happened to chat with Oli Sennhauser (former colleague from MySQL AB) who now runs the FromDual MySQL/MariaDB consulting firm in Switzerland, and he’s been working with Galera for quite a long time. He recognised the pattern and said that he too had that experience, and he thought =0 might be the better option.
I delved into the InnoDB source code to see what was actually happening, and the code indeed concurs with what’s described in the manual (that hasn’t always been the case ;-). I also verified this with Jeremy Cole whom we may happily regard as guru on “how InnoDB actually works”. The once-per-second flush (and optional preceding write) is performed by the InnoDB master thread. Take a peek in log/log0log.c and trx/trx0trx.c, specifically trx_commit_off_kernel() and srv_sync_log_buffer_in_background().
In conclusion:
- Even with =0, the log does get written and flushed once per second. This is done in the background so connection threads don’t have to wait for it.
- There is no setting where there is never a flush/fsync.
- With =2, the writing of the log takes place in the connection thread and this appears to incur a significant overhead, at least relative to =0. Aside from the writing of the log at transaction commit, there doesn’t appear to be a difference.
- Based on the preceding points, I would say that if you don’t want =1, you might as well set =0 in order to get the performance you’re after. There is of course a slight practical difference between =0 and =2. With =2 the log is immediately written. If the mysqld process were to crash within a second after that, the OS would close the file and have that log write stored. With =0 that log data wouldn’t have been written. If the OS or machine fails, that log write is lost either way.
In production environments, we tend to mainly want to mitigate trouble from system failures, so =0 appears to be a suitable/appropriate option – for a Galera cluster environment.
What remains is the question of why the log write operation appears to reduce transaction commit performance so much, in a way more so than the flush/fsync. Something to investigate further!
Your thoughts?