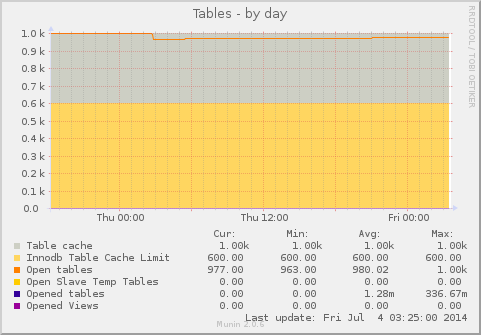
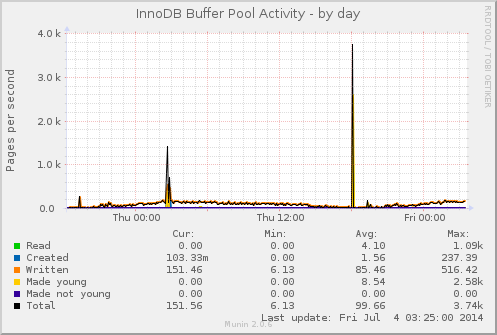
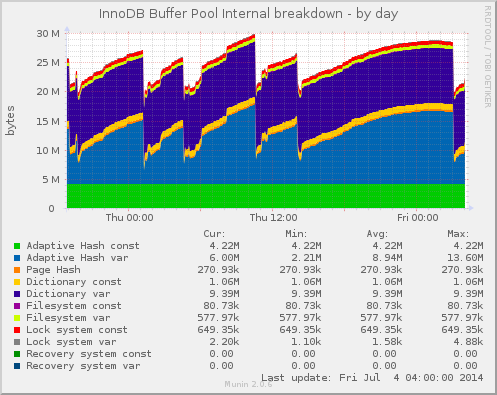
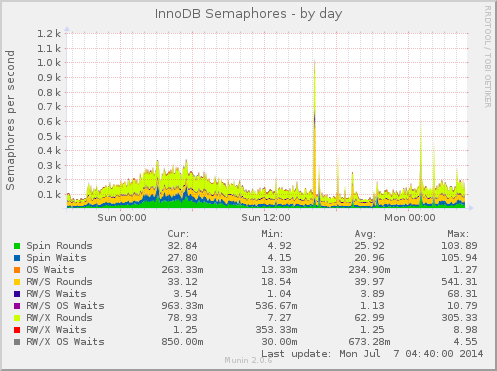
Open Source is a whole-of-process approach to development that can produce high-quality products better tailored to users’ real world needs. A key reason for this is the early feedback cycle built into that complete process.
Simply publishing something under an Open Source license (while not applying Open Source development processes) does not yield the same quality and other benefits. So, not all Open Source is the same.
Publishing source of a product “later” (for instance when the monetary benefit has diminished for the company) is meaningless. In this scenario, there is no “Open Source benefit” to users whatsoever, it’s simply a proprietary product. There is no opportunity for the client to make custom modifications or improvements, or ask a third party to work on such matters – neither is there any third party opportunity to verify and validate either code quality or security.
Open Source is not a marketing gimmick. Labels such as “Open Source”, or “Enterprise”, on their own, do not have any more positive outcome than a greasy hamburger labeled with “healthy”. If a company “believes” in Open Source software, they’ll use the open source development model for their software development.
And now we see things like this: Uproar: MariaDB Corp. veers away from open source (by Simon Phipps, InfoWorld, August 2016)
So what does it mean when a company publishes some of their software under an open source license, and does some related products under a proprietary license? To me, it’s generally a strong indication that the company either doesn’t believe in that model, or doesn’t understand it. And we’ve seen it before.
It also reminds me of an interaction I had many years ago. A Marketing VP asked me “How can we leverage our [Open Source] community?” I answered the only possible way: “One does not ‘leverage’ the community, that’s not how it works.” Of course that wasn’t the answer the VP wanted to hear, but that doesn’t make it less true. They saw the community as an asset to use, rather than work with. People don’t like getting used, and in the Open Source space that’s even more true.
Companies that have turned their back on their earlier Open Source work and who have devised some other model to (arguably) make more money, have all discovered that this fundamentally changes their market. They’ll lose some of their users, customers and supporters, and gain some new different clients. It’s a different market. Whether and how that pans out in terms of commercial success is never certain. Given that we know that the Open Source development process yields benefits in terms of quality and features users want, we can say that non-OSS products lack (some of) those benefits, so to put it bluntly, it’ll be a different product of possibly less quality and the feature set is likely to differ as well.
Naturally we cannot ascertain code quality directly as we can’t review closed code directly, bug systems of proprietary software tends to be closed, changelogs are condensed for marketing purposes, but as far back as a decade and a half there have been independent studies that worked out “lines of code per software flaw” and it came out significantly in favour of Open Source software, having proportionally much fewer bugs. Bugs also tend to get fixed quicker in Open Source software. None of this is new(s). see for instance Open-source vs. proprietary software bugs: Which get squashed fastest? (CNET, 2007)
For complete products (libraries are a slightly different beast) with a relatively large market scope, source code being available does not in any way diminish a company’s ability to make money. Having the core developers, tech writers and support people gives them a significant edge in the open market, and that’s a business asset you can leverage. You do that by focusing on those aspects in your communications – that’s basic marketing, you draw attention to the positive aspects that make your company/product stand out from the rest. Clearly, this objective cannot not achieved by force, as you don’t make a (potential) client like or trust you by denying them choice or transparency.
There is one other known option aside from not believing or not understanding, and that’s fear. But fear is an awkward business driver, it makes for very bad decisions.
MariaDB Corp in part uses the Open Source development model, in part they’re an Open Source publisher (in-house work that’s only made available at a later stage in the development process), and now some proprietary product has been added to the mix (actually new versions of an existing product). Looking at this I am rather unclear about what they believe in. Of course companies can make business choices as they see fit – but they never operate in a vacuum. In the end it doesn’t matter much what I believe personally, the market will do what it will – historically, it responds in the various ways as described above. We’ll see how it pans out.
Open Query does not recommend (or re-sell at all) proprietary tools, as it just doesn’t make sense for us or our clients. We often do bugfixes and improvements which we contribute upstream – for proprietary tools we can’t do that and thus it becomes a hindrance for us and our clients. On the specific practical level, we’ve actually never used MaxScale (the product that MariaDB Corp will now sell under different conditions for future versions), and this stems from our experience with its effective predecessor MySQL Proxy. Having a complex set of scripted logic in a proxy slows down applications and introduces a rather large extra (single) point of potential failure in to infrastructure. So, while Simon refers to MaxScale as an essential tool for scale-able environments, we know from experience that there are other ways of achieving that desired objective, and without the downsides.
Rather than promoting a single tool for many wildly different jobs, we utilise a few different tools depending on the needs of particular client infrastructure. We still have a couple of (now legacy) MySQL-MMM deployments, but also quite a few Galera clusters, and other setups as suit our clients’ needs. Key is to not only make the infrastructure convenient to use for applications, but also to not introduce any more single points of failure. We build resilience into the client’s server infrastructure, without adding significant overhead in either performance or maintenance requirements.
We believe that that’s what clients want, and since potential clients come to us asking exactly for that (and note our approach with relief) we think that we’re doing the right thing by our clients. We’ve used this approach for over 9 years, and we’ll just keep on doing that – our basic approach doesn’t change even when our tools do. If you’d like to talk with us about helping you with your infra, using our approach and way of working, contact us today!

 One of the key problems with the 2016 online census was the architecture, but also the how the whole thing was organised and who was contracted for the job.
One of the key problems with the 2016 online census was the architecture, but also the how the whole thing was organised and who was contracted for the job.