In MariaDB 10.2.12, these two don’t yet work together. GTID = Global Transaction ID. In the master-slave asynchronous replication realm, this means that you can reconnect a slave to another server (change its master) and it’ll happily continue replicating from the correct point. No more fussing with filenames and offsets (which of course will both differ on different machines).
So in concept the GTIID is “globally” unique – that means it’s consistent across an entire infra: a binlogged write transaction will have the same GTID no matter on which machine you look at it.
OK: if you are transitioning from async replication to Galera cluster, and have a cluster as slave of the old infra, then GTID will work fine.
PROBLEM: if you want to run an async slave in a Galera cluster, GTID will currently not work. At least not reliably.
The overview issue is MDEV-10715, the specific problem is documented in MDEV-14153 with some comments from me from late last week. MDEV-14153 documents cases where the GTID is not in fact consistent – and the way in which it isn’t is most disturbing.
The issue appears as “drift”. A GTID is made up of R-S-# where R is replication domain (0 unless set by an app), S for server-id where the write was originally done, and # which is just a number. The only required rule for the # is that that each next event has to have a higher number than the previous. In principle there could be #s missing, that’s ok.
In certain scenarios, the # part of the GTID falls behind on the “other nodes” in the Galera cluster. There was the node where the statement was first issued, and then there are the other nodes which pick up the change through the Galera (wsrep) cluster mechanism. Those other nodes. So at that point, different nodes in the cluster have different GTIDs for the same query. Not so great.
To me, this looked like a giant red flag though: if a GTID is assigned on a commit, and then replicated through the cluster as part of that commit, it can’t change. Not drift, or any other change. So the only possible conclusion must be that it is in fact not passed through the cluster, but “reinvented” by a receiving cluster node, which simply assumes that the current event from a particular server-id is previous-event id + 1. That assumption is false, because as I mentioned above it’s ok for gaps to exist. As long as the number keeps going up, it’s fine.
Here is one of the simplest examples of breakage (extract from a binlog, with obfuscated table names):
# at 12533795
#180704 5:00:22 server id 1717 end_log_pos 12533837 CRC32 0x878fe96e GTID 0-1717-1672559880 ddl
/*!100001 SET @@session.gtid_seq_no=1672559880*//*!*/;
# at 12533837
#180704 5:00:22 server id 1717 end_log_pos 12534024 CRC32 0xc6f21314 Query thread_id=4468 exec_time=0 error_code=0
SET TIMESTAMP=1530644422/*!*/;
SET @@session.time_zone='SYSTEM'/*!*/;
DROP TEMPORARY TABLE IF EXISTS `qqq`.`tmp_foobar` /* generated by server */
/*!*/;
Fact: temporary tables are not replicated (imagine restarting a slave, it wouldn’t have whatever temporary tables were supposed to exist). So, while this event is stored in the binary log (which it is to ensure that if you replay the binlog on a machine, it correctly drops the temporary table after creating and using it), it won’t go through a cluster. Remember that Galera cluster is essentially a ROW-based replication scheme; if there are changes in non-temporary tables, of course they get replicated just fine. So if an app creates a temporary table, does some calculations, and then inserts the result of that into a regular table, the data of that last bit will get replicated. As it should. In a nutshell, as far as data consistency goes, we’re all fine.
But the fact that we have an event that doesn’t really get replicated creates the “fun” in the “let’s assume the next event is just the previous + 1” logic. This is where the drift comes in. Sigh.
In any case, this issue needs to be fixed by let’s say “being re-implemented”: the MariaDB GTID needs to be propagated through the Galera cluster, so it’s the same on every server, as it should be. Doing anything else is always going to go wrong somewhere, so trying to catch more cases like the above example is not really the correct way to go.
If you are affected by this or related problems, please do vote on the relevant MDEV issues. That is important! If you need help tracking down problems, feel free to ask. If you have more information on the matter, please comment too! I’m sure this and related bugs will be fixed, there are very capable developers at MariaDB Corp and Codership Oy (the Galera company). But the more information we can provide, the better. It often helps with tracking down problems and creating reproducible test cases.
In Amazon space, any EC2 or Service instance can “disappear” at any time. Depending on which service is affected, the service will be automatically restarted. In EC2 you can choose whether an interrupted instance will be restarted, or left shutdown.
For an Aurora instance, an interrupted instance is always restarted. Makes sense.
The restart timing, and other consequences during the process, are noted in our post on Aurora Failovers.
Aurora Testing Limitations
As mentioned earlier, we love testing “uncontrolled” failovers. That is, we want to be able to pull any plug on any service, and see that the environment as a whole continues to do its job. We can’t do that with Aurora, because we can’t control the essentials:
power button;
reset switch;
ability to kill processes on a server;
and the ability to change firewall settings.
In Aurora, an instance is either running, or will (again) be running shortly. So that we know. Aurora MySQL also offers some commands that simulate various failure scenarios, but since they are built-in we can presume that those scenarios are both very well tested, as well as covered by the automation around the environment. Those clearly defined cases are exactly the situations we’re not interested in.
What if, for instance, a server accepts new connections but is otherwise unresponsive? We’ve seen MySQL do this on occasion. Does Aurora catch this? We don’t know and we have no way of testing that, or many other possible problem scenarios. That irks.
The Need to Know
If an automated system is able to catch a situation, that’s great. But if your environment can end up in a state such as described above and the automated systems don’t catch and handle it, you could be dead in the water for an undefined amount of time. If you have scripts to catch cases such as these, but the automated systems catch them as well, you want to be sure that you don’t trigger “double failovers” or otherwise interfere with a failover-in-progress. So either way, you need to know and and be aware whether a situation is caught and handled, and be able to test specific scenarios.
In summary: when you know the facts, then you can assess the risk in relation to your particular needs, and mitigate where and as desired.
A corporate guarantee of “everything is handled and it’ll be fine” (or as we say in Australia “She’ll be right, mate!“) is wholly unsatisfactory for this type of risk analysis and mitigation exercise. Guarantees and promises, and even legal documents, don’t keep environments online. Consequently, promises and legalities don’t keep a company alive.
So what does? In this case, engineers. But to be able to do their job, engineers need to know what parameters they’re working with, and have the ability to test any unknowns. Unfortunately Aurora is, also in this respect, a black box. You have to trust, and can’t comprehensively verify. Sigh.
Right now Aurora only allows a single master, with up to 15 read-only replicas.
Master/Replica Failover
We love testing failure scenarios, however our options for such tests with Aurora are limited (we might get back to that later). Anyhow, we told the system, through the RDS Aurora dashboard, to do a failover. These were our observations:
Role Change Method
Both master and replica instances are actually restarted (the MySQL uptime resets to 0).
This is quite unusual these days, we can do a fully controlled role change in classic asynchronous replication without a restart (CHANGE MASTER TO …), and Galera doesn’t have read/write roles as such (all instances are technically writers) so it doesn’t need role changes at all.
Failover Timing
Failover between running instances takes about 30 seconds. This is in line with information provided in the Aurora FAQ.
Failover where a new instance needs to be spun up takes 15 minutes according to the FAQ (similar to creating a new instance from the dash).
Instance Availability
During a failover operation, we observed that all connections to the (old) master, and the replica that is going to be promoted, are first dropped, then refused (the connection refusals will be during the period that the mysqld process is restarting).
According to the FAQ, reads to all replicas are interrupted during failover. Don’t know why.
Aurora can deliver a DNS CNAME for your writer instance. In a controlled environment like Amazon, with guaranteed short TTL, this should work ok and be updated within the 30 seconds that the shortest possible failover scenario takes. We didn’t test with the CNAME directly as we explicitly wanted to observe the “raw” failover time of the instances themselves, and the behaviour surrounding that process.
Caching State
On the promoted replica, the buffer pool is saved and loaded (warmed up) on the restart; good! Note that this is not special, it’s desired and expected to happen: MySQL and MariaDB have had InnoDB buffer pool save/restore for years. Credit: Jeremy Cole initially came up with the buffer pool save/restore idea.
On the old master (new replica/slave), the buffer pool is left cold (empty). Don’t know why. This was a controlled failover from a functional master.
Because of the server restart, other caches are of course cleared also. I’m not too fussed about the query cache (although, deprecated as it is, it’s currently still commonly used), but losing connections is a nuisance. More detail on that later in this article.
Statistics
Because of the instance restarts, the running statistics (SHOW GLOBAL STATUS) are all reset to 0. This is annoying, but should not affect proper external stats gathering, other than for uptime.
On any replica, SHOW ENGINE INNODB STATUS comes up empty. Always. This seems like obscurity to me, I don’t see a technical reason to not show it. I suppose that with a replica being purely read-only, most running info is already available through SHOW GLOBAL STATUS LIKE ‘innodb%’, and you won’t get deadlocks on a read-only slave.
Multi-Master
Aurora MySQL multi-master was announced at Amazon re:Invent 2017, and appears to currently be in restricted beta test. No date has been announced for general availability.
We’ll have to review it when it’s available, and see how it works in practice.
Conclusion
Requiring 30 seconds or more for a failover is unfortunate, this is much slower than other MySQL replication (writes can failover within a few seconds, and reads are not interrupted) and Galera cluster environments (which essentially delivers continuity across instance failures – clients talking to the failed instance will need to reconnect to the loadbalancer/cluster to continue).
I don’t understand why the old master gets a cold InnoDB buffer pool.
I wouldn’t think a complete server restart should be necessary, but since we don’t have insight in the internals, who knows.
On Killing Connections (through the restart)
Losing connections across an Aurora cluster is a real nuisance that really impacts applications. Here’s why:
When MySQL C client library (which most MySQL APIs either use or are modelled on) is disconnected, it passes back a specific error to the application. When the application makes its next query call, the C client will automatically reconnect first (so the client does not have to explicitly reconnect). So a client only needs to catch the error and re-issue its last command, and all will generally be fine. Of course, if it relies on different SESSION settings, or was in the middle of a multi-statement transaction, it will need to do a bit more.
So, this means that the application has to handle disconnects gracefully without chucking hissy-fits at users, and I know for a fact that that’s not how many (most?) applications are written. Consequently, an Aurora failover will make the frontend of most applications look like a disaster zone for about 30 seconds (provided functional instances are available for the failover, which is the preferred and best case scenario).
I appreciate that this is not directly Aurora’s fault, it’s sloppy application development that causes this, but it’s a real-world fact we have to deal with. And, perhaps importantly: other cluster and replication options do not trigger this scenario.
Our clients operate on a variety of platforms, and RDS (Amazon Relational Database Service) Aurora has received quite a bit of attention in recent times. On behalf of our clients, we look beyond the marketing, and see what the technical architecture actually delivers. We will address specific topics in individual posts, this time checking out what the Aurora architecture means for write and caching behaviour (and thus performance).
What is RDS Aurora?
First of all, let’s declare the baseline. MySQL Aurora is not a completely new RDBMS. It comprises a set of Amazon modifications on top of stock Oracle MySQL 5.6 and 5.7, implementing a different replication mechanism and some other changes/additions. While we have some information (for instance from the “deep dive” by AWS VP Anurag Gupta), the source code of the Aurora modifications are not published, so unfortunately it is not immediately clear how things are implemented. Any architecture requires choices to be made, trade-offs, and naturally these have consequences. Because we don’t get to look inside the “black box” directly, we need to explore indirectly. We know how stock MySQL is architected, so by observing Aurora’s behaviour we can try to derive how it is different and what it might be doing. Mind that this is equivalent to looking at a distant star, seeing a wobble, and deducing from the pattern that there must be one or more planets orbiting. It’s an educated guess.
For the sake of brevity, I have to skip past some aspects that can be regarded as “obvious” to someone with insight into MySQL’s architecture. I might also defer explaining a particular issue in depth to a dedicated post on that topic. Nevertheless, please do feel free to ask “so why does this work in this way”, or other similar questions – that’ll help me check my logic trail and tune to the reader audience, as well as help create a clearer picture of the Aurora architecture.
Instead of using the binary log, Aurora replication ties into the storage layer. It only supports InnoDB, and instead of doing disk reads/writes, the InnoDB I/O system talks to an Amazon storage API which delivers a shared/distributed storage, which can work across multiple availability zones (AZs). Thus, a write on the master will appear on the storage system (which may or may not really be a filesystem). Communication between AZs is fairly fast (only 2-3 ms extra overhead, relative to another server in the same AZ) so clustering databases or filesystems across AZs is entirely feasible, depending on the commit mechanism (a two-phase commit architecture would still be relatively slow). We do multi-AZ clustering with Galera Cluster (Percona XtraDB Cluster or MariaDB Galera Cluster). Going multi-AZ is a good idea that provides resilience beyond a single data centre.
So, imagine an individual instance in an Aurora setup as an EC2 (Amazon Elastic Computing) instance with MySQL using an SSD EBS (Amazon Elastic Block Storage) volume, where the InnoDB I/O threads interface more directly the the EBS API. The actual architecture might be slightly different still (more on that in a later post), but this rough description helps set up a basic idea of what a node might look like.
Writes in MySQL
In a regular MySQL, on commit a few things happen:
the InnoDB log is written to and flushed,
the binary log is written to (and possibly flushed), and
the changed pages (data and indexes) in the InnoDB buffer pool are marked dirty, so a background thread knows they need to be written back to disk (this does not need to happen immediately). When a page is written to disk, normally it uses a “double-write” mechanism where first the original page is read and written to a scratch space, and then the new page is put in the original position. Depending on the filesystem and underlying storage (spinning disk, or other storage with different block size from InnoDB page size) this may be required to be able to recover from write fails.
This does not translate in to as many IOPS because in practice, transaction commits are put together (for instance with MariaDB’s group commit) and thus many commits that happen in a short space effectively only use a few IOs for their log writes. With Galera cluster, the local logs are written but not flushed, because the guaranteed durability is provided with other nodes in the cluster rather than local persistence of the logfile.
In Aurora, a commit has to send either the InnoDB log entries or the changed data pages to the storage layer; which one it is doesn’t particularly matter. The storage layer has a “quorum set” mechanism to ensure that multiple nodes accept the new data. This is similar to Galera’s “certification” mechanism that provides the “virtual synchrony”. The Aurora “deep dive” talk claims that it requires many fewer IOPS for a commit; however, it appears they are comparing a worst-case plain MySQL scenario with an optimal Aurora environment. Very marketing.
Aurora does not use the binary log, which does make one wonder about point-in-time recovery options. Of course, it is possible to recover to any point-in-time from an InnoDB snapshot + InnoDB transaction logs – this would require adding timestamps to the InnoDB transaction log format.
While it is noted that the InnoDB transaction log is also backed up to S3, it doesn’t appear to be used directly (so, only for recovery purposes then). After all, any changed page needs to be communicated to the other instances, so essentially all pages are always flushed (no dirty pages). When we look at the InnoDB stats GLOBAL STATUS, we sometimes do see up to a couple of dozen dirty pages with Aurora, but their existence or non-existence doesn’t appear to have any correlation with user-created tables and data.
Where InnoDB gets its Speed
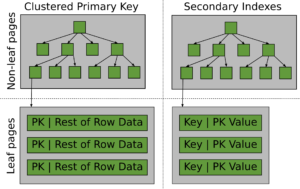
InnoDB rows and indexing
We all know that disk-access is slow. In order for InnoDB to be fast, it is dependent on most active data being in the buffer pool. InnoDB does not care for local filesystem buffers – something is either in persistent storage, or in the buffer pool. In configurations, we prefer direct I/O so the system calls that do the filesystem I/O bypass the filesystem buffers and any related overhead. When a query is executed, any required page that’s not yet in the buffer pool is requested to be loaded in the background. Naturally, this does slow down queries, which is why we preferably want all necessary pages to already be in memory. This applies for any type of query. In InnoDB, all data/indexes are structured in B+trees, so an INSERT has to be merged into a page and possibly causes pages to be split and other items shuffled so as to “re-balance” the tree. Similarly, a delete may cause page merges and a re-balancing operation. This way the depth of the tree is controlled, so that even for a billion rows you would generally see a depth of no more than 6-8 pages. That is, retrieving any row would only require a maximum of 6-8 page reads (potentially from disk).
I’m telling you all this, because while most replication and clustering mechanisms essentially work with the buffer pool, Aurora replication appears to works against it. As I mentioned: choices have consequences (trade-offs). So, what happens?
Aurora Replication
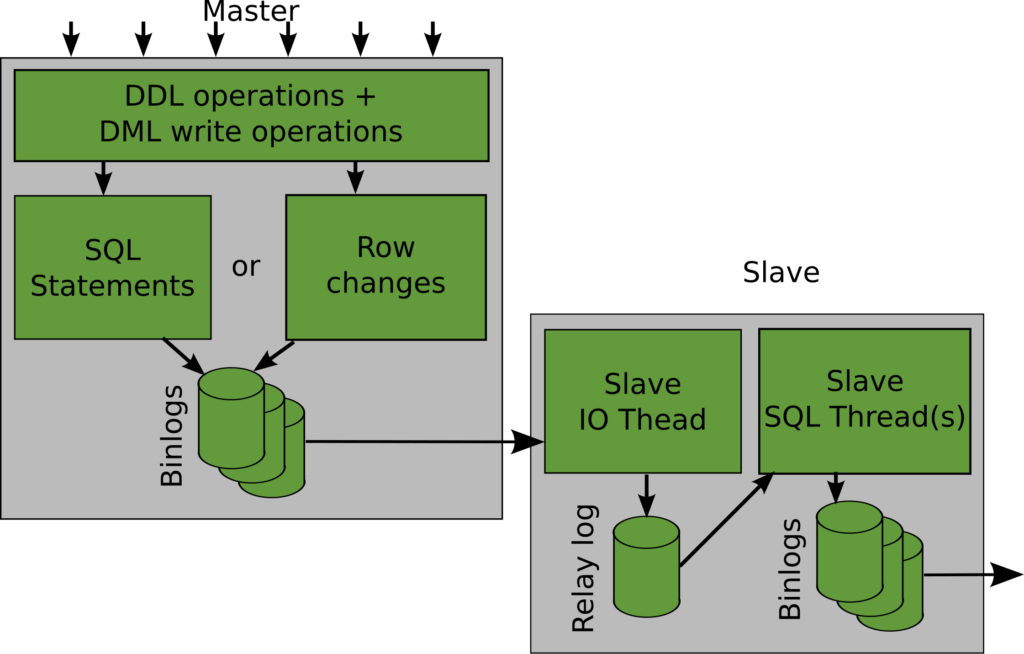
When you do a write in MySQL which gets replicated through classic asynchronous replication, the slaves or replica nodes affect the row changes in memory. This means that all the data (which is stored with the PRIMARY KEY, in InnoDB) as well as any other indexes are updated, the InnoDB log is written, and the pages marked as dirty. It’s very similar to what happens on the writer/master system, and thus the end result in memory is virtually identical. While Galera’s cluster replication operates differently from the asynchronous mechanism shown in the diagram, the resulting caching (which pages are in memory) ends up similar.
MySQL Replication architecture
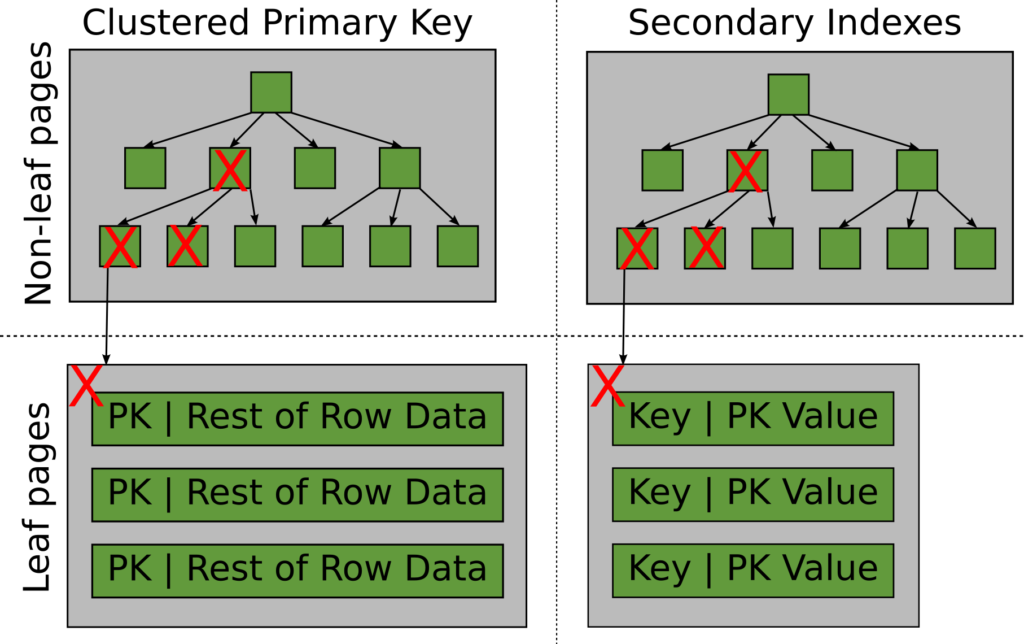
Not so with Aurora. Aurora replicates in the storage layer, so all pages are updated in the storage system but not in the in-memory InnoDB buffer pool. A secondary notification system between the instances ensures that cached InnoDB pages are invalidated. When you next do a query that needs any of those no-longer-valid cached pages, they will have to be be re-read from the storage system. You can see a representation of this in the diagram below, indicating invalidated cache pages in different indexes; as shown, for INSERT operations, you’re likely to have pages higher up in the tree and one sideways page change as well because of the B+tree-rebalancing.
Aurora replicated insert
The Chilling Effect
We can tell the replica is reading from storage, because the same query is much slower than before we did the insert from the master instance. Note: this wasn’t a matter of timing. Even if we waited slightly longer (to enable a possible background thread to refresh the pages) the post-insert query was just as slow.
Interestingly, the invalidation process does not actually remove them from the buffer pool (that is, the # of pages in the buffer pool does not go down); however, the # of page reads does not go up either when the page is clearly re-read. Remember though that a status variable is just that, it has to be updated to be visible and it simply means that the new functions Amazon implemented don’t bother updating these status variables. Accidental omission or purposeful obscurity? Can’t say. I will say that it’s very annoying when server statistics don’t reflect what’s actually going on, as it makes the stats (and their analysis) meaningless. In this case, the picture looks better than it is.
With each Aurora write (insert/update/delete), the in-memory buffer pool on replicas is “chilled”.
Unfortunately, it’s not even just the one query on the replica that gets affected after a write. The primary key as well as the secondary indexes get chilled. If the initial query uses one particular secondary index, that index and the primary key will get warmed up again (at the cost of multiple storage system read operations), however the other secondary indexes are still chattering their teeth.
Being Fast on the Web
In web applications (whether websites or web-services for mobile apps), typically the most recently added data is the most likely to be read again soon. This is why InnoDB’s buffer pool is normally very effective: frequently accessed pages remain in memory, while lesser used ones “age” and eventually get tossed out to make way for new pages.
Having caches clear due to a write, slows things down. In the MySQL space, the fairly simply query cache is a good example. Whenever you write to table A, any cached SELECTs that accesses table A are cleared out of the cache. Regardless of whether the application is read-intensive, having regular writes makes the query cache useless and we turn it off in those cases. Oracle has already deprecated the “good old” query cache (which was introduced in MySQL 4.0 in the early 2000s) and soon its code will be completely removed.
Conclusion
With InnoDB, you’d generally have an AUTO_INCREMENT PRIMARY KEY, and thus newly inserted rows are sequenced to that outer end of the B+Tree. This also means that the next inserted row often ends up in the same page, again invalidating that recently written page on the replicas and slowing down reads of any of the rows it contained.
For secondary indexes, the effect is obviously scattered although if the indexed column is temporal (time-based), it will be similarly affected to the PRIMARY KEY.
How much all of this slows things down will very much depend on your application DB access profile. The read/write ratio will matter little, but rather whether individual tables are written to fairly frequently. If they do, SELECT queries on those tables made on replicas will suffer from the chill.
Aurora uses SSD EBS so of course the storage access is pretty fast. However, memory is always faster, and we know that that’s important for web application performance. And we can use similarly fast SSD storage on EC2 or another hosting provider, with mature scaling technologies such as Galera (or even regular asynchronous multi-threaded replication) that don’t give your caches the chills.
The following quirky dynamic SQL will scan each index of each table so that they’re loaded into the key_buffer (MyISAM) or innodb_buffer_pool (InnoDB). If you also use the PBXT engine which does have a row cache but no clustered primary key, you could also incorporate some full table scans.
To make mysqld execute this on startup, create /var/lib/mysql/initfile.sql and make it be owned by mysql:mysql
SET SESSION group_concat_max_len=100*1024*1024;
SELECT GROUP_CONCAT(CONCAT('SELECT COUNT(`',column_name,'`) FROM `',table_schema,'`.`',table_name,'` FORCE INDEX (`',index_name,'`)') SEPARATOR ' UNION ALL ') INTO @sql FROM information_schema.statistics WHERE table_schema NOT IN ('information_schema','mysql') AND seq_in_index = 1;
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET SESSION group_concat_max_len=@@group_concat_max_len;
and in my.cnf add a line in the [mysqld] block
init-file = /var/lib/mysql/initfile.sql
That’s all. mysql reads that file on startup and executes each line. Since we can do the whole select in a single (admittedly quirky) query and then use dynamic SQL to execute the result, we don’t need to create a stored procedure.
Of course this kind of simplistic “get everything” only really makes sense if the entire dataset+indexes fit in memory, otherwise you’ll want to be more selective. Still, you could use the above as a basis, perhaps using another table to provide a list of tables/indexes to be excluded – or if the schema is really stable, simply have a list of tables/indexes to be included instead of dynamically using information_schema.
Practical (albeit niche) application:
In a system with multiple slaves, adding in a new slave makes it start with cold caches, but since with loadbalancing it will pick up only some of the load it often works out ok. However, some environments have dual masters but the application is not able to do read/write splits to utilise slaves. In that case all the reads also go to the active master. Consequentially, the passive master will have relatively cold caches (only rows/indexes that have been updated will be in memory) so in case of a failover the amount of disk reads for the many concurrent SELECT queries will go through the roof – temporarily slowing the effective performance to a dismal crawl: each query takes longer with the required additional disk access so depending on the setup the server may even run out of connections which in turn upsets the application servers. It’d sort itself out but a) it looks very bad on the frontend and b) it may take a number of minutes.
The above construct prevents that scenario, and as mentioned it can be used as a basis to deal with other situations. Not many people know about the init-file option, so this is a nice example.
If you want to know how the SQL works, read on. The original line is very long so I’ll reprint it below with some reformatting:
SELECT GROUP_CONCAT(CONCAT(
'SELECT COUNT(`',column_name,'`)
FROM `',table_schema,'`.`',table_name,
'` FORCE INDEX (`',index_name,'`)'
) SEPARATOR ' UNION ALL ')
INTO @sql
FROM information_schema.statistics
WHERE table_schema NOT IN ('information_schema','mysql')
AND seq_in_index = 1;
The outer query grabs each regular db/table/index/firstcol name that exists in the server, writing out a SELECT query that counts all not-NULL values of the indexed column (so it must scan the index), forcing that specific index. We then abuse the versatile and flexible GROUP_CONCAT() function to glue all those SELECTs together, with “UNION ALL” inbetween. The result is a single very long string, so we need to tweak the maximum allowed group_concat output beforehand to prevent truncation.
We got good responses to the “identify this query profile” question. Indeed it indicates an SQL injection attack. Obviously a code problem, but you must also think about “what can we do right now to stop this”. See the responses and my last note on it below the original post.
Got a new one for you!
You find a system with broken replication, could be a slave or one in a dual master setup. the IO thread is still running. but the SQL thread is not and the last error is (yes the error string is exactly this, very long – sorry I did not paste this string into the original post – updated later):
“Could not parse relay log event entry. The possible reasons are: the master’s binary log is corrupted (you can check this by running ‘mysqlbinlog’ on the binary log), the slave’s relay log is corrupted (you can check this by running ‘mysqlbinlog’ on the relay log), a network problem, or a bug in the master’s or slave’s MySQL code. If you want to check the master’s binary log or slave’s relay log, you will be able to know their names by issuing ‘SHOW SLAVE STATUS’ on this slave.”
In other similar cases the error message is about something else but the query it shows with it makes no sense. To me, that essentially says the same as the above.
The server appears to have been restarted recently.
What’s wrong, and what’s your quickest way to get replication going again given this state?
A little challenge for you… given an existing app that does not know about separate master/slave connections, and you want to enable working in a replicated infrastructure. Simply redirecting all SELECTs to the slave connection will not work. Why?
Hint: there are at least two reasons, depending on other factors. There may be more.
Comments are set to be moderated so providing answers will not spoil it for others. I’ll leave it run for a bit and then approve all comments.

 In Amazon space, any EC2 or Service instance can “disappear” at any time. Depending on which service is affected, the service will be automatically restarted. In EC2 you can choose whether an interrupted instance will be restarted, or left shutdown.
In Amazon space, any EC2 or Service instance can “disappear” at any time. Depending on which service is affected, the service will be automatically restarted. In EC2 you can choose whether an interrupted instance will be restarted, or left shutdown. Right now Aurora only allows a single master, with up to 15 read-only replicas.
Right now Aurora only allows a single master, with up to 15 read-only replicas.