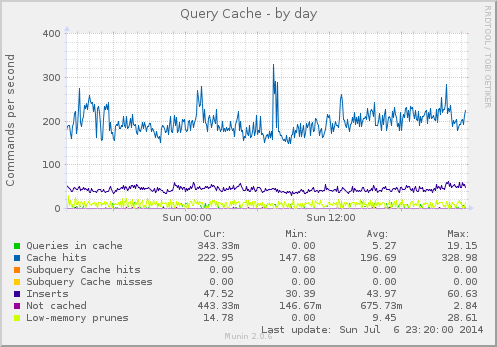
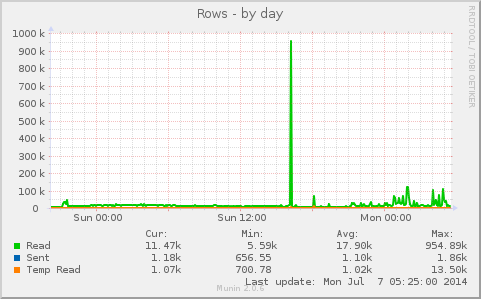
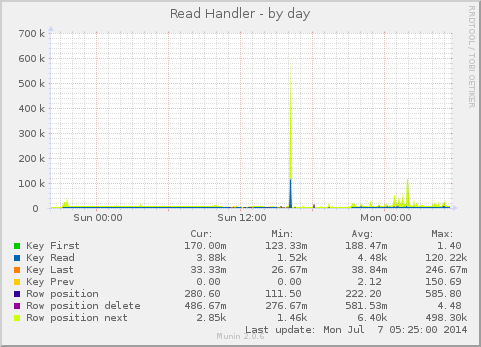
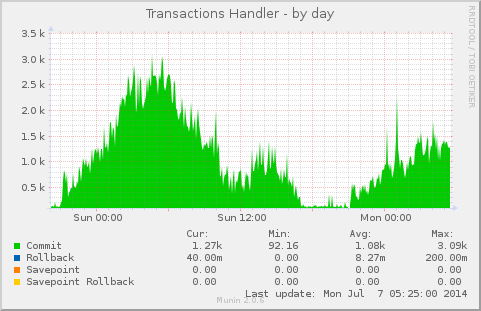
Multi-threaded replication is a new feature introduced in MySQL 5.6 and MariaDB 10.0. In traditional single-threaded replication, the slaves have a disadvantage as they have to process in sequence what a master executed in parallel. This, plus the fact that slaves usually have a lot of read-only connections to deal with as well, can easily create performance problems. That is, a single-threaded slave needs to be set to allow fewer connections, otherwise there’s a higher risk of it not being able to keep up with the replication stream. There is no exact rule for this, as it relates to general I/O capacity and fsync latency, as well as general CPU and RAM considerations and query patterns.
Currently, it appears that the MariaDB implementation is a bit more mature in terms of design and effective implementation. For instance, MySQL 5.6 does not currently support retrying transactions while doing parallel replication. This can easily cause problems as commit conflicts are possible and obviously need to be handled. So for the purpose of this blog post, we’re going to focus on MariaDB 10.0, and it is what we currently use with some of our clients. MariaDB developer Kristian Nielsen has done awesome work and is very responsive to questions and bug reports. Rock on, Kristian!
The fundamental challenge for parallel replication is that some queries are safe to be executed in parallel, and some are not – and somehow, the server needs to know which is which. MariaDB employs two strategies to assist with this:
- Group commit. Since 5.5, transactions (remember, a standalone statement without START TRANSACTION/COMMIT is technically also a transaction) that happen around the same time in different connections are grouped in the binary log and effectively committed together. This is accomplished by the server trying to gather at least a certain number of transactions (binlog_commit_wait_count) and having individual connections wait just a fraction (binlog_commit_wait_usec) to increase the chances of gathering a nice number. This strategy reduces I/O and fsyncs, and thus helps quite a bit with write scaling. The miniscule delay that a transaction might incur because it has to wait is easily offset by the overall better performance. It’s good stuff. For the purpose of parallel replication, any transactions in the same group commit can in principle be executed in parallel on a slave – conflicts are possible, so deadlock handling and retries are essential.
- Global Transaction IDs (GTID) Domain IDs (gtid_domain_id) in MariaDB 10.0, which an application can set within a connection. Quite often, different applications and different components of applications use the same database server, but their actions are completely independent: no write operations will ever conflict between the different applications. GTID Domain IDs allows us to tell the server about this, allowing it to always run those transactions in parallel even if they weren’t part of the same group commit! Now that’s a real bonus!
Now, as a practicality, we’re not always able to modify applications to for instance set the GTID Domain ID. Plus, a magic (integer) number is required and so we need some planning/coordination between completely independent applications! Through database server consolidation, you may get applications on your server that were previously on a different one – strictly speaking having two applications use the same GTID Domain ID is harmless (after all, by default all transactions run in the same domain!) but obviously it doesn’t improve performance.
Open Query engineer Daniel Black and I came up with the following. It’s a combination of MySQL’s init_connect system variable (gets called when a user connects, except if they have SUPER privilege), a few stored procedures, and an event to keep the domain map reasonably up-to-date. The premise of this implementation is that each database username uniquely identifies an application, and that no two usernames refer to the same application. So, if you have for instance a general application user but also one for background scripts or one with special administrative privileges, then you need to modify the code in setdomain() a bit to take this into account. If you have transactions with a different GTID Domain ID execute in parallel on the same database, obviously this can cause conflicts. The MariaDB slave threads will retry, but in some cases conflicts cannot be resolved by retrying.
Obviously it’s not perfect, but it does resolve the issue for many situations. Feedback and improvements welcome!
# Automatic GTID Domain IDs for MariaDB 10.0
# Copyright (C) 2014 by Daniel Black & Arjen Lentz, Open Query Pty Ltd (http://openquery.com.au)
# Version 2014-11-18, initial publication via OQ blog (https://openquery.com.au/blog/)
#
# This work is licensed under Creative Commons Attribution-ShareAlike 4.0 International
# http://creativecommons.org/licenses/by-sa/4.0/
USE mysql
DELIMITER //
DROP PROCEDURE IF EXISTS setdomain //
CREATE PROCEDURE setdomain(IN cuser varchar(140)) DETERMINISTIC READS SQL DATA SQL SECURITY DEFINER
BEGIN
DECLARE EXIT HANDLER FOR NOT FOUND SET SESSION gtid_domain_id=10;
# modify this logic for your particular application/user naming convention
SELECT domain INTO @l_gtid_domain_id
FROM mysql.user_domain_map
WHERE user=LEFT(cuser, LOCATE('@',cuser) -1 );
SET SESSION gtid_domain_id=@l_gtid_domain_id;
END //
DROP PROCEDURE IF EXISTS create_user_domain_map //
CREATE PROCEDURE create_user_domain_map() MODIFIES SQL DATA
BEGIN
DECLARE u CHAR(80);
DECLARE h CHAR(60);
DECLARE userhostcur CURSOR FOR SELECT user,host FROM mysql.user;
DECLARE EXIT HANDLER FOR NOT FOUND FLUSH PRIVILEGES;
CREATE TABLE IF NOT EXISTS mysql.user_domain_map
(
domain INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
user CHAR(80) COLLATE utf8_bin NOT NULL UNIQUE
) AUTO_INCREMENT=10, ENGINE=InnoDB;
INSERT IGNORE INTO mysql.user_domain_map(user)
SELECT user FROM mysql.user;
OPEN userhostcur;
LOOP FETCH userhostcur INTO u,h;
INSERT IGNORE INTO mysql.procs_priv(Host,Db,User, Routine_name, Routine_type, Grantor, Proc_priv)
VALUES(h, 'mysql', u, 'setdomain', 'PROCEDURE', CURRENT_USER(), 'Execute');
END LOOP;
END;//
DELIMITER ;
# (re)create the user domain map
CALL create_user_domain_map();
# set up event schedule
CREATE EVENT update_user_domain_map ON SCHEDULE EVERY 1 DAY DO CALL create_user_domain_map();
# also set this in my.cnf so it's persistent
# init_connect='CALL mysql.setdomain(current_user());'
SET GLOBAL init_connect='CALL mysql.setdomain(current_user());';