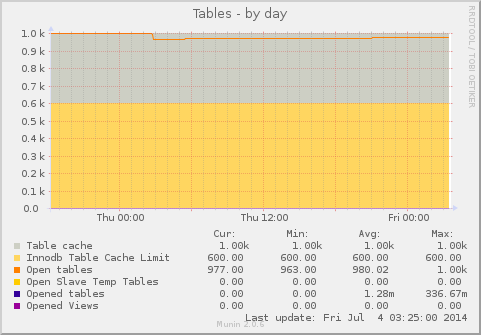
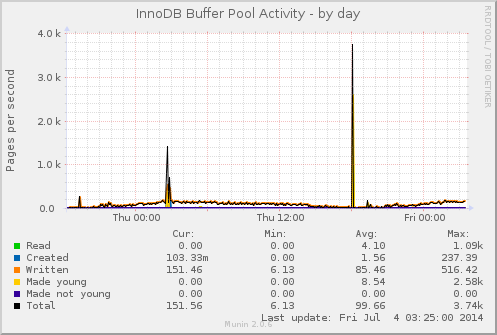
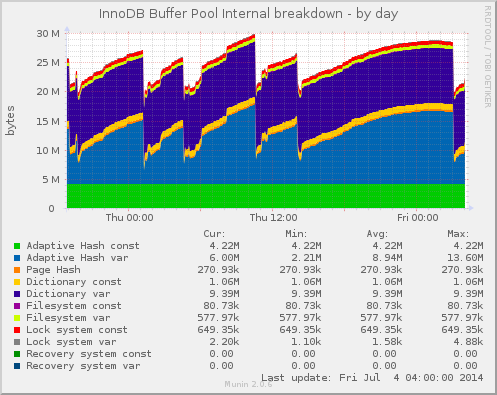
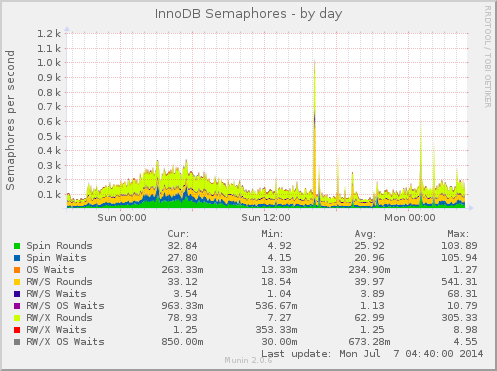
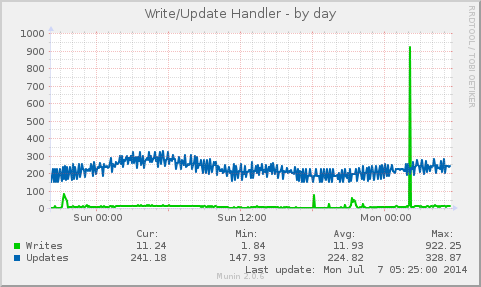
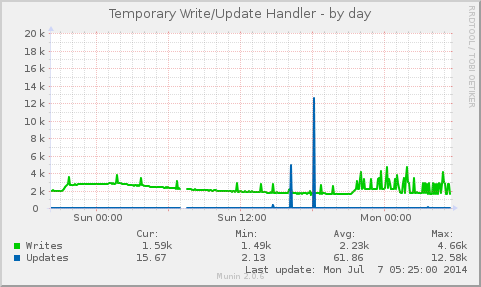
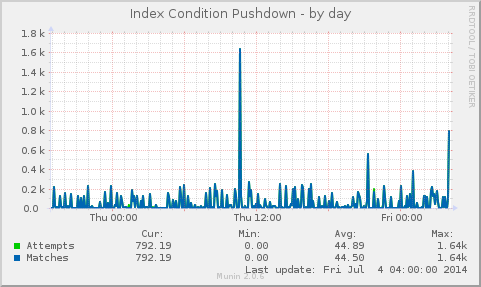
I’ve previously covered how user perspective and that browser to web server latency is a dominate cause of web server performance issues.
Assuming you’ve resolved those as best as you can how to you measure server performance at a per request level. Web servers allow you to put their processing time into the logs however its not there by default.
Using Nginx you can define a custom format by adding $request_time:
log_format extended '$remote_addr - $remote_user [$time_local] '
'"$request" $status $request_time $body_bytes_sent '
'"$http_referer" "$http_user_agent"';
access_log [current access log file] extended;
In Apache’s HTTPd you can do a similar thing using %D:
LogFormat "%h %l %u %t \"%r\" %>s %D %b \"%{Referer}i\" \"%{User-agent}i\"" extended
CustomLog [current access log file] extended
After you’ve collected a meaningful sample of web activity you’re ready to analyse. First step copy the logs off all web servers to a common directory.
Second combine the logs. Assuming you haven’t played with the time format in the log, logmerge using –apache-access is a good way to get a single log even with the Nginx format above.
logmerge --apache-access *access.log > weball.log
Assuming your time is in the 10th column like I’ve done in the example. The following will put the slowest responses at the top.
sort -n -r -k 10 --parallel=8 weball.log > weball-sort.log
Take a look though and look at what’s here.
If you consider more that 4 seconds for a response is slow lets move all those requests to their own file. The grep here is matching the first response of 0, 1, 2 or 3 seconds in the sorted log.
grep -n -m 1 'HTTP/1\.[01]" 200 [0123]\.' weball-sort.log
42435:127.0.0.1 - - [02/Oct/2012:22:24:33 -0400] "POST /search ...
This will print the first line that has a response time beginning with 0,1,2 or 3. Because its sorted all lines before this are bigger. So lets put that in its own file.
head -n {linenumber - 1} weball-sort.log > weball-sort-more-than-4-seconds.log
To group these by URL path and get some frequency counts:
cut -f 8 -d ' ' web-access-sorted-time-more-than-4-seconds.log | sort | uniq -c | sort -n -r
6377 /new-releases
3753 /userrecommendations/index
2160 /home
1073 /bestsellers/reviewed
1048 /myfantasicproduct
563 /category/cool/10
464 /category/fun/17
395 /index.php?do=/blog/add/
....
From this you should start to recognise some URL patterns that need attention.
Take a note of these. And we’ll use statistics to see how these really are across all logs. I didn’t find a good simple number counter quickly enough so I’m using the modified one as attached. Compile with gcc stat.c -o stat -lm. This should compile on any ansi C compiler. It takes numbers as the input and calculates output when the EOF is reached.
/* stat.c
* This program reads numbers from standard input and outputs
* sum, mean and standard deviation.
*
* Rewritten by Daniel Black of Open Query
*
* To build:
* gcc stat.c -o stat -lm
*
* originally based of:
* http://www.dreamincode.net/forums/topic/138734-sum-mean-median-max-min-standard-deviation-in-c/
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
int main(void)
{
long unsigned count = 0;
double sum_sqrs = 0, total = 0, max = 0, min = 0, mean = 0, std_dev = 0, var = 0;
int res = 0;
float tmp;
/* Read inputs from the console window */
res = scanf("%f", &tmp);
if (res == EOF) return 0;
count = 1;
min = max = total = tmp;
sum_sqrs = tmp * tmp;
while(1)
{
res = scanf("%f", &tmp);
if (res == EOF) break;
count += res;
if(tmp < min) min = tmp;
if(tmp > max) max = tmp;
total += tmp;
sum_sqrs += tmp * tmp;
}
printf("Count: %lu\n", count);
printf("Sum of All Values: %.2f: \n", total);
mean = total / count;
printf("Mean of Values: %.2f: \n", mean);
printf("Minimum value entered: %.2f: \n", min);
printf("Maximum value entered: %.2f: \n", max);
var = sum_sqrs / count - mean*mean;
std_dev = sqrt(var);
printf("Standard Deviation: %.2f\n", std_dev);
return 0;
}
So:
fgrep "GET /home" weball.log | cut -f 11 -d ' ' | ./stat
Count: 47438
Sum of All Values: 69947.67:
Mean of Values: 1.47:
Minimum value entered: 0.00:
Maximum value entered: 200.00:
Standard Deviation: 1.83
Assuming this is a normal like distribution 97% of responses will lie within mean + 2* standard deviation so 5.13 seconds. Acceptable? up to you.
There’s still a 200 second maximum on this. Though there shouldn’t be that many outlying entries we’ll need to look at this to see its significance.
How many took more than 10 seconds?
fgrep 'GET /home' web-access-sorted-time-slowest-40000.log| egrep -v 'HTTP/1\.[01]" [0-9]{3} [0-9]\.' | wc -l
61
So 61 request out of 47438? Using “more” instead of “wc -l” will enable you to see some responses. Sometimes it a property of the dataset that causes these particular pages to be slow so even a particularly low number here may be worth examining.
Repeating the above steps for other URLs is a pretty good way of identifying problem pages by examining the frequency, mean, standard deviation and the business value of the page. So now you just need to dive into the mechanics of the page and work out what’s being slow.
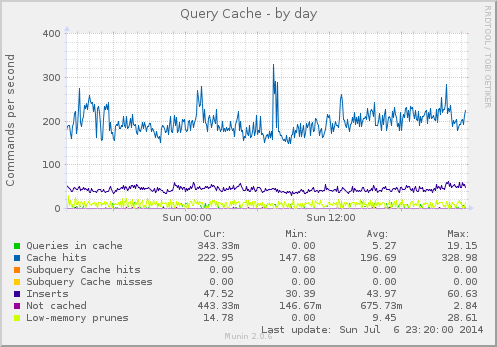
Aside if you’re interested in graphing:
If you want to do XY graphs using the time as a X column I suggest using logmerge’s –tempfile option then:
sed -i -e 's/^\(..............\)_\([^ ]*\)\(.*\)/\1\3/g' logfile
After this and the first column with be a YYYYMMDDHHMMSS time and thus usable on an X axis. I was having trouble using Libreoffice Calc for this on a 2 million line log file though putting the file with a .csv extension helped.